
Inversion
Reconstruction comparison between pretrained (EG3D-PTI), full fine-tuning, and our method. Full fine-tuning requires 31M trainable parameters per identity, while our method requires only ~0.2M trainable parameters per identity.
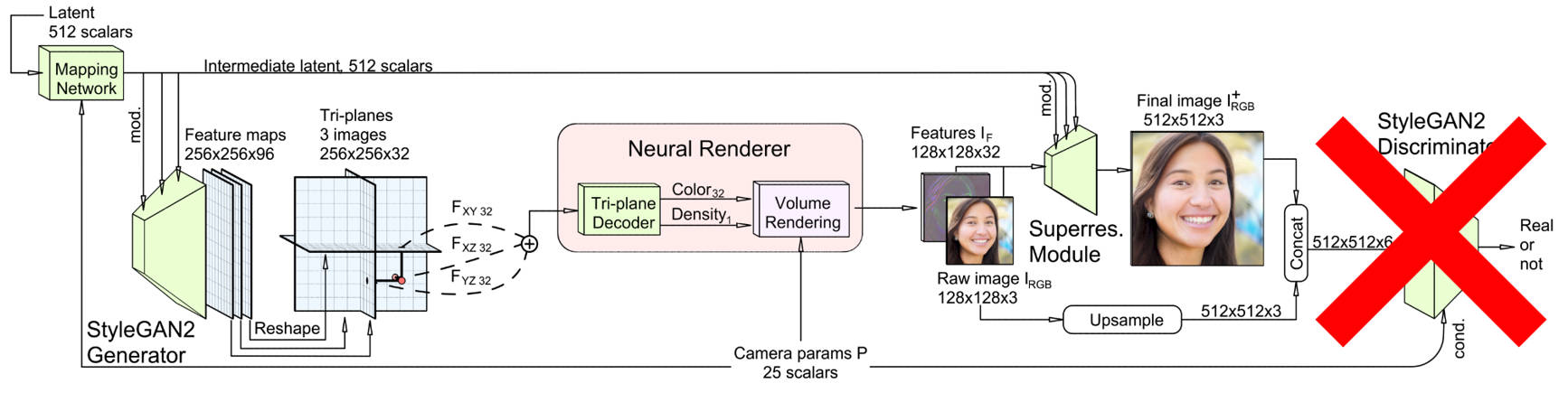
In recent years, generative 3D face models (e.g., EG3D) have been developed to tackle the problem of synthesizing photo-realistic faces. However, these models are often unable to capture facial features unique to each individual, highlighting the importance of personalization. Some prior works have shown promise in personalizing generative face models, but these studies primarily focus on 2D settings. Also, these methods require both fine-tuning and storing a large number of parameters for each user, posing a hindrance to achieving scalable personalization. Another challenge of personalization is the limited number of training images available for each individual, which often leads to overfitting when using full fine-tuning methods.
Our proposed approach, My3DGen, generates a personalized 3D prior of an individual using as few as 50 training images. My3DGen allows for novel view synthesis, semantic editing of a given face (e.g. adding a smile), and synthesizing novel appearances, all while preserving the original person's identity. We decouple the 3D facial features into global features and personalized features by freezing the pre-trained EG3D and training additional personalized weights through low-rank decomposition. As a result, My3DGen introduces only $\textbf{240K}$ personalized parameters per individual, leading to a $\textbf{127}\times$ reduction in trainable parameters compared to the $\textbf{30.6M}$ required for fine-tuning the entire parameter space. Despite this significant reduction in storage, our model preserves identity features without compromising the quality of downstream applications.
Image Inversion


Image Interpolation


Image Synthesis


Image Enhancement


Semantic Editing


Reconstruction comparison between pretrained (EG3D-PTI), full fine-tuning, and our method. Full fine-tuning requires 31M trainable parameters per identity, while our method requires only ~0.2M trainable parameters per identity.
Interpolating between anchor pairs. Interpolation is performed between two anchors on the extreme left and right column (shown in blue).
Interpolating between two latent codes. We can also animate novel appearance (expression, hairstyle, etc.) by interpolating the latent codes of two input anchors. Use the slider here to linearly interpolate between the left anchor and the right anchor (including the pose).

Left anchor

Right anchor
Sampling latent codes from $\alpha$-space. you can synthesize unlimited novel appearances without changing the model weights. Uncurated samples are shown below.
|
Kamala Harris
|
||||
|
Pretrained
|







|
|||
|
My3DGen
|







|
|||
|
Barack Obama
|
||||
|
Pretrained
|







|
|||
|
My3DGen
|







|
|||
|
Scarlett Johansson
|
||||
|
Pretrained
|







|
|||
|
My3DGen
|







|
|||
Using Semantic Editing, you can perform attribute editing using the latent code without changing the model weights. Input image is shown on the left, followed by the multi-view reconstruction of the edited image. With the same latent code, ours preserves the identity information while editing the attributes.
|
Adding smile to Dwayne Johnson
|
||||
|
Pretrained
|


|
|||
|
My3DGen
|


|
|||
|
Removing smile from Kamala Harris
|
||||
|
Pretrained
|


|
|||
|
My3DGen
|


|
|||
3D GAN inversion using one single image can lead to identity drift when pose changes $i.e.$ it does not look like the same person when changing the pose (see image inversion results above or see Stable3D for more details).
More specifically, inversion technique can achieve the best pixel-wise reconstruction results under the same pose as the input image but may not be able to preserve the identity under different poses. Because the model is inferring faces using the knowledge learned from the pretrained prior (FFHQ) when the pose is different from the input image's pose. Thus it may either fail to reconstruct the face or reconstruct a different face under different poses.
On the other hand, personalization is inferring the faces under different poses using the knowledge learned from training selfies.
Better multi-view consistency and less training data required - see MyStyle for more details.
LoRA can help reduce artifacts caused by overfitting. We find that full-finetuning models tend to overfit to the training data and forget the pretrained knowledge. This can lead to artifacts in the downstream tasks e.g. in inversion task, naive finetuning can introduce rendering floaters and artifacts in facial texture/shape (see inverion results in main pdf).
We thank Jun Myeong Choi, Akshay Paruchuri, and Nurislam Tursynbek for reviewing early drafts and suggesting helpful improvements. We thank Tianlong Chen and Yotam Nitzan for thoughtful discussions and feedback during the course of this research.
@misc{qi2024my3dgenscalablepersonalized3d,
title={My3DGen: A Scalable Personalized 3D Generative Model},
author={Luchao Qi and Jiaye Wu and Annie N. Wang and Shengze Wang and Roni Sengupta},
year={2024},
eprint={2307.05468},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2307.05468},
}